How to Create a Twitter Streaming Pipeline with Tweepy, Apache Kafka, and Amazon RDS for PostgreSQL in Python
Introduction
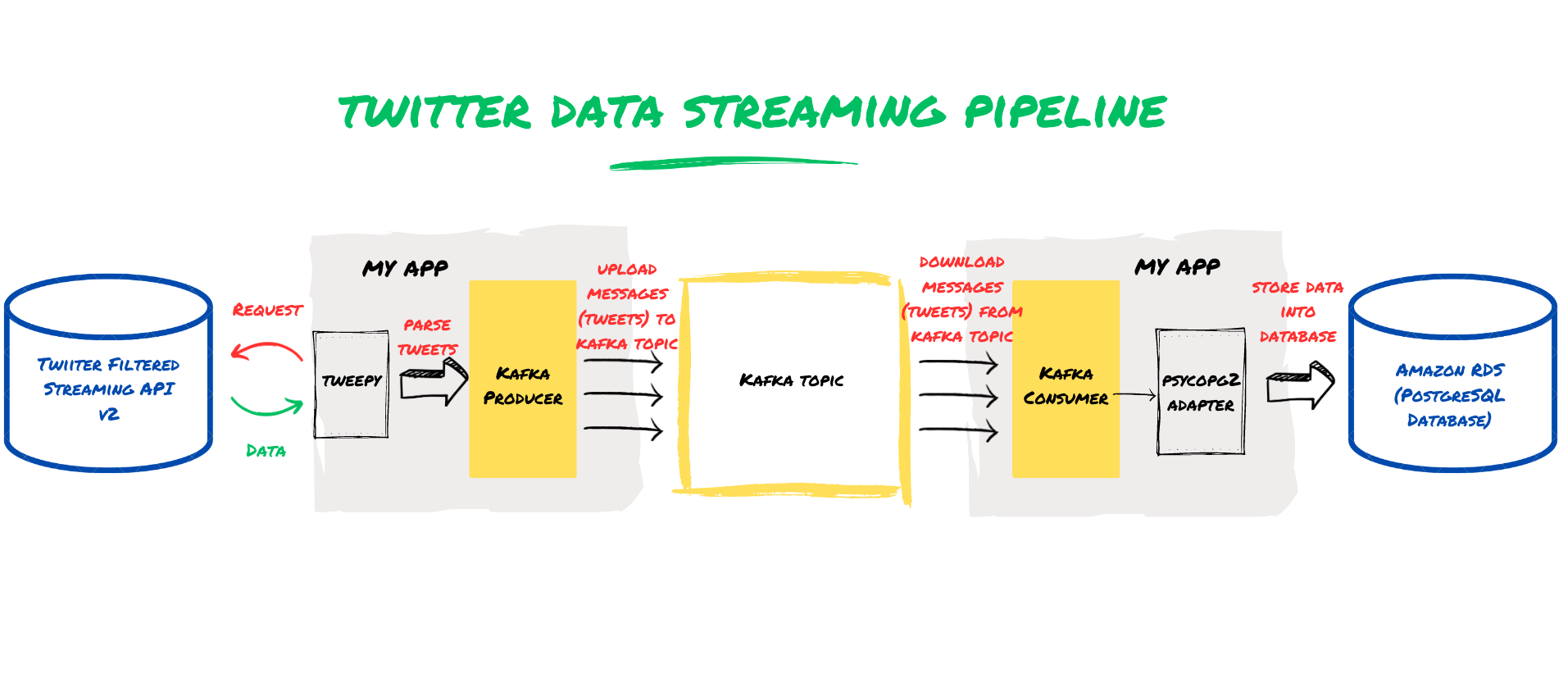
Twitter, with its millions of active users and real-time conversations, is a particularly rich source of data that can be harnessed for a wide range of applications, from sentiment analysis and customer feedback to market research and trend analysis. In this blog, I will demonstrate you how to set up a Twitter streaming pipeline on your local machine using Python Tweepy, Apache Kafka, and Amazon RDS for PostgreSQL, which will allow us to collect and store real-time tweets in a reliable and scalable manner. By following this step-by-step guide, you will be able to collect real-time data from Twitter and use it for business use-cases. Whether you’re a data scientist, software engineer, or business analyst, this tutorial will equip you with the tools and techniques you need to start harnessing the power of Twitter data today.
Unlock valuable consumer insights with our tailored solutions for Twitter analytics.
Pre-requisites
In order to develop the Twitter streaming pipeline using Tweepy, Apache Kafka, and Amazon RDS for PostgreSQL, there are a few prerequisites that need to be met. First, you will need to have a Twitter developer account and obtain the necessary API keys and tokens, which are required to access Twitter’s streaming API. Additionally, you will need to have Python installed on your machine, as well as the necessary Python libraries, including Tweepy, Kafka-python, and psycopg2. While I assume that the reader already knows how to install Python on their machine, I have included the links that will help you installing the required libraries. It is also important to note that you will need an Amazon Web Services (AWS) account to set up a PostgreSQL database on Amazon RDS. Finally, basic knowledge of SQL and database management will be helpful in understanding some of the later steps in the pipeline. By ensuring that these prerequisites are met, you will be well on your way to creating your own Twitter streaming pipeline.
Creating a Twitter Developer account.
To create a Twitter developer account and obtain the necessary API keys and tokens, please refer to the official Twitter developer documentation for the step-by-step instructions. (Link: https://developer.twitter.com/en/support/twitter-api/developer-account)
Installing Tweepy, Python-Kafka, and Psycopg2
To install Tweepy, Python-Kafka, and Psycopg2, please refer to their official documentation for detailed installation instructions. Here are the links to their respective installation guides:
- Tweepy: https://docs.tweepy.org/en/latest/install.html
- Python-Kafka: https://kafka-python.readthedocs.io/en/master/install.html
- Psycopg2: https://www.psycopg.org/docs/install.html
Make sure to follow the instructions carefully and verify that the installation is successful before proceeding to the next steps.
Apache Kafka Setup
- Download and install Apache Kafka from the official website. (Link: https://kafka.apache.org/downloads)
- Start the Zookeeper server and Kafka server on your local drive (I will present cloud-based solution in our next blog). The Zookeeper server is required to manage the Kafka cluster, while the Kafka server is the core component that processes the data.
- Create a Kafka topic. You will be pushing your tweet data to this topic.
Tips.
Navigate to the Kafka install directory on your computer and start both servers by entering the following commands on your terminal.
Setting up PostgreSQL Database with Amazon RDS
To create an Amazon Web Services (AWS) account and to create a new RDS instance, please refer to the official documentation. (Link: https://aws.amazon.com/getting-started/hands-on/create-connect-postgresql-db/
Amazon RDS documentation provides detailed instructions and best practices for setting up and managing RDS instances, so be sure to follow them closely to ensure optimal performance and security.
Twitter Streaming Service using Twitter API and Kafka Producer
Twitter’s streaming API allows developers to collect real-time data from Twitter’s public stream of tweets. This service is especially useful for businesses or data scientists looking to track public opinion, monitor brand reputation, or analyze trends. We will be using Twitter API v2 endpoints and Tweepy to interact with v2 endpoints in our project. Tweepy is a Python library that simplifies the process of accessing the Twitter API and collecting Twitter data.
To collect tweets streamed from Twitter in real-time, we will use Apache Kafka Producer to send the tweets to a Kafka topic. Kafka is a distributed streaming platform that allows for the processing of large streams of data in real-time. In the code provided below, we will learn how to use Tweepy and a Kafka producer to stream tweets from Twitter’s API and send them to a Kafka topic.
Import libraries
Define Kafka Producer
To use Kafka as a messaging system to send real-time tweets, we need to create a Kafka producer object in Python. The get_kafka_producer() function defined below creates a KafkaProducer object and initializes it with the bootstrap servers and a value serializer function that converts the message to JSON format. We will call this function from the main() method to get the Kafka producer object.
By using the KafkaProducer object, we can send the messages (tweets) to the Kafka broker that will store and distribute them to the subscribed consumers.
Create Custom Class for StreamingClient
The StreamingClient class is used to filter and sample realtime Tweets with Twitter API v2. It takes bearer_token as the required argument for authenticating with the Twitter API. To add some custom functionality, we’ve created a custom class StreamListener that inherits from StreamingClient. This custom class allows us to handle large volumes of real-time data efficiently by sending tweets to a Kafka topic in batches using the queue library. We have included custom arguments using super() for performing the required operations.
In the StreamListener class, the on_connect function is used to check the connection status for your API credentials. The on_tweet function is used to retrieve incoming tweets using the tweet object. We’ve specified some custom code to parse the incoming tweet, store relevant message (tweet data) in a dictionary and handle sending of message to Kafka topic in batches using the queue library. This process avoids overloading the Kafka topic and storing duplicate tweets in the queue. Additionally, we’ve defined two callback functions: on_send_success and on_send_error. The on_send_success function handles delivery reports for the tweet data sent to the Kafka topic, while the on_send_error function handles error reports. Both of these functions print messages to the console and log messages to a log file.
Overall, the StreamListener class provides a way to efficiently handle large volumes of real-time tweet data by sending the data to a Kafka topic in batches.
At this stage, you can run your program and test whether the filtered tweets are being sent to the Kafka topic by starting the Kafka consumer console using the following command on your terminal. This will start consuming the messages from the Kafka topic and print them to the console.
Note that the Zookeeper server and the Kafka server should be running (see Apache Kafka Setup) for producer to continuously push messages to the Kafka topic.
Call StreamListener and Producer from main function
In this code snippet, we define the main() function that is the entry point for our program. The main() function sets up the Kafka producer using get_kafka_producer() function and a filtered tweet listener using StreamListener class.
We pass the following arguments to the StreamListener constructor to set up the listener: topic = ‘data-science-tweets’, producer = kafka_producer, batch_size = 100, wait_on_rate_limit = True. The streaming rules for filtering tweets containing data science keywords are added using the add_rules() method of the StreamListener object. We start the filtered streaming using the filter() method of the StreamListener object. This method will continuously run and listen to incoming tweets, and send them to the Kafka topic using the kafka_producer.send().
The KeyboardInterrupt exception is handled in case we want to stop the program manually by pressing ctrl+C.
At my agency SARDA DataWorks, we specialize in providing consulting and strategic solutions for startup businesses looking to harness the power of data from the early stage. Our expertise in data collection, analyses, interpretation, and prediction to generate meaningful insights allows us to provide customized solutions tailored to your specific needs. Contact us today to book a free consult to learn about how we can help you make data-driven decisions.
Tweet Loader Service using Kafka Consumer
Tweet Loader Service is an essential component of the real-time tweet processing system, which allows you to consume tweets stored in Kafka topics for further processing. The loader service is responsible for consuming the tweets, parsing them, and storing them in a database or performing further analysis.
Define Kafka Consumer
To implement the Tweet Loader Service, we need to set up an Apache Kafka Consumer object. The Kafka consumer subscribes to the Kafka topic, retrieves tweets, and store them in a data store or perform further processing. The get_kafka_consumer() function creates a KafkaConsumer object and initializes it with the topic name and bootstrap servers. We will call this function from the main() method to get the Kafka consumer object.
Create a separate Thread for Kafka Consumer processing
In this step, a separate thread is created for the consumer processing to efficiently process the tweets consumed from the Kafka topic in real-time. This approach prevents blocking of the main thread and ensures that the tweets are being processed in the background as they are consumed from the Kafka topic.
The code below demonstrates how to create a separate thread for consumer processing in the Tweet Loader Service. We define a TweetConsumer class that extends the threading.Thread class, and we implement the run() method. This method continuously polls the Kafka topic for new tweets and processes them in batches.
In the run() method, we set a batch size of 100 tweets, and we continuously poll the Kafka topic with a timeout of 1000 milliseconds until new tweets are available. When the tweets are available, they are processed in batches, and each batch is inserted into the Amazon cloud database using the insert_tweet_data() function.
Call Consumer from main function
In order to run the Tweet Loader Service, we need to call the get_kafka_consumer() function to set up the Kafka Consumer. After that, we’ll start a new separate thread for consumer, which retrieves messages from the topic and sends them to the database for storage. Below is the modified main() function with the Kafka Consumer implementation:
By adding this section, we can now run the Kafka consumer in the main() method and start retrieving messages from the topic for processing.
Inserting Tweets into PostgreSQL Database on Amazon Relational Database Service (RDS)
The final step is to store the data collected from Twitter in a database for further analysis. In this section, we will go over the process of inserting tweets into a PostgreSQL database running on Amazon RDS.
Connecting to PostgreSQL database to Insert Tweets into Database
To establish a connection to the PostgreSQL database, we use the psycopg2 module, which is a PostgreSQL adapter for the Python programming language. After establishing the connection to the PostgreSQL database, we can use a function to insert tweet data into relevant tables. The following code snippet shows how to connect to a PostgreSQL database on Amazon RDS using credentials. The function insert_tweet_data(tweet) is defined to add tweet data to the database. This function was called from run() method of the TweetConsumer class as shown in section Kafka Consumer processing
It is assumed that you have set-up Amazon RDS for PostgreSQL (read section Setting up PostgreSQL Database with Amazon RDS) and you have created a database with a table and columns to store tweet data.
Closing Thoughts
Creating a Twitter streaming service is a powerful way to collect real-time data from Twitter and use it for various customer centric engagement and data science applications. In this blog post, we’ve shown you how to create a simple real-time application for Twitter streaming pipeline using Tweepy, Kafka, and PostgreSQL. Tweepy interacts with the Twitter API and live stream filtered tweets. By leveraging Kafka’s scalability, we showed how to stream a large volume of tweets in real-time and store them for future analysis. We also demonstrated how to use Python to write a Kafka producer and consumer, connect to a PostgreSQL database using Python, and add data to the database on Amazon RDS. By following this step-by-step guide, you can learn how to set up a real-time streaming pipeline that captures data from Twitter, stores it in a database, and provides a foundation for more advanced analytics.
I invite you to leave comments or questions, subscribe to my blog, and follow me on social media to stay up-to-date with the latest tips for data analysis and data science. I value your feedback and look forward to hearing from you.



Leave a comment